
redis服务器是基于事件驱动机制实现的。
所谓事件驱动是指,根据发生的事件(比如点击鼠标)进行相应的处理。一般事件驱动程序由
事件收集器,事件分发器,事件处理器三部分组成。事件收集器负责接收事件(包括来自用户的或软件硬件的事件),事件分发器负责将事件发送到相应的事件处理器程序,事件处理器则负责处理具体事件。
redis中的事件有文件事件和时间事件两类。redis自己实现了一套事件驱动机制(类似libevent),用来处理这两类事件。
- 文件事件
redis服务器通过
套接字与客户端或其他redis服务器连接。 文件事件是服务器对套接字操作的抽象。 服务器与客户端或其他服务器的通信会产生相应的文件事件,服务器通过监听并处理这些文件事件,来完成一系列网络通信操作。 redis基于reactor模式开发了自己的网络事件处理器,称作文件事件处理器。 - 时间事件 redis服务器中需要有一些固定时间点执行的操作,时间事件就是对这类定时操作的抽象。
事件处理流程
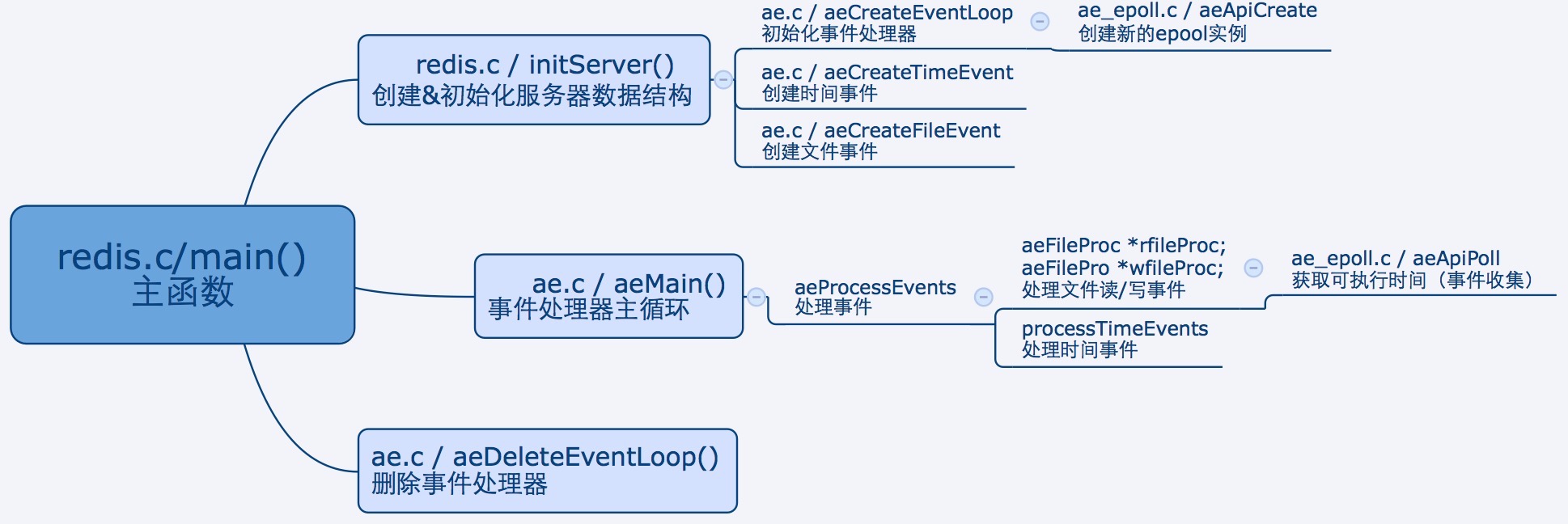
redis.c / main() 函数
//redis.c文件,main函数
int main(int argc, char **argv) {
...
//1.创建并初始化服务器数据结构
initServer();
...
//2. 运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
//3. 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
return 0;
}
1. 初始化事件处理器
redis.c 的main()函数中调用initServer(),该函数调用aeCreateEventLoop初始化事件处理器。
//redis.c文件,创建并初始化服务器数据结构
struct redisServer server; //全局变量,redis服务器全局状态
void initServer(){
...
//1. 初始化事件处理器状态
server.el = aeCreateEventLoop(server.maxclients+REDIS_EVENTLOOP_FDSET_INCR);
...
}
//ae.c文件,初始化事件处理器
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
// 创建事件状态结构
if ((eventLoop = zmalloc(sizeof(*eventLoop))) == NULL) goto err;
// 初始化文件事件结构和已就绪文件事件结构数组
eventLoop->events = zmalloc(sizeof(aeFileEvent)*setsize);
eventLoop->fired = zmalloc(sizeof(aeFiredEvent)*setsize);
if (eventLoop->events == NULL || eventLoop->fired == NULL) goto err;
// 设置数组大小
eventLoop->setsize = setsize;
// 初始化执行最近一次执行时间
eventLoop->lastTime = time(NULL);
// 初始化时间事件结构
eventLoop->timeEventHead = NULL;
eventLoop->timeEventNextId = 0;
eventLoop->stop = 0;
eventLoop->maxfd = -1;
eventLoop->beforesleep = NULL;
//以epoll为例,创建epool实例,并赋值给eventLoop的apidata字段
if (aeApiCreate(eventLoop) == -1) goto err;
/* Events with mask == AE_NONE are not set. So let's initialize the
* vector with it. */
// 初始化监听事件
for (i = 0; i < setsize; i++)
eventLoop->events[i].mask = AE_NONE;
// 返回事件循环
return eventLoop;
err:
if (eventLoop) {
zfree(eventLoop->events);
zfree(eventLoop->fired);
zfree(eventLoop);
}
return NULL;
}
2. 创建时间事件
在initServer()中调用aeCreateTimeEvent创建时间事件。
//redis.c文件,创建并初始化服务器数据结构
void initServer(){
...
//2. 为 serverCron() 创建时间事件
if(aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
redisPanic("Can't create the serverCron time event.");
exit(1);
}
...
}
long long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds,
aeTimeProc *proc, void *clientData,
aeEventFinalizerProc *finalizerProc)
{
// 更新时间计数器
long long id = eventLoop->timeEventNextId++;
// 创建时间事件结构
aeTimeEvent *te;
te = zmalloc(sizeof(*te));
if (te == NULL) return AE_ERR;
// 设置 ID
te->id = id;
// 设定处理事件的时间
aeAddMillisecondsToNow(milliseconds,&te->when_sec,&te->when_ms);
// 设置事件处理器
te->timeProc = proc;
te->finalizerProc = finalizerProc;
// 设置私有数据
te->clientData = clientData;
// 将新事件放入表头
te->next = eventLoop->timeEventHead;
eventLoop->timeEventHead = te;
return id;
}
3. 注册文件I/O事件
在initServer()中调用aeCreateFileEvent注册文件I/O事件,利用系统提供的I/O多路复用技术(select、epoll等)监听感兴趣的I/O事件。
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
if (fd >= eventLoop->setsize) {
errno = ERANGE;
return AE_ERR;
}
if (fd >= eventLoop->setsize) return AE_ERR;
// 取出文件事件结构
aeFileEvent *fe = &eventLoop->events[fd];
// 监听指定 fd 的指定事件
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
// 设置文件事件类型,以及事件的处理器
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
// 私有数据
fe->clientData = clientData;
// 如果有需要,更新事件处理器的最大 fd
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}
4. 监听事件
initServer()中提供了TCP和UNIX域套接字两种方式进行监听。
void initServer(){
...
// 3. 为 TCP 连接关联连接应答(accept)处理器
// 用于接受并应答客户端的 connect() 调用
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
redisPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
// 为本地套接字关联应答处理器
if (server.sofd > 0 && aeCreateFileEvent(server.el,server.sofd,AE_READABLE,
acceptUnixHandler,NULL) == AE_ERR) redisPanic("Unrecoverable error creating server.sofd file event.");
...
}
5. redis事件循环
initServer()完成上述准备工作后,回到main()函数,main()中会调用aeMain(),进入事件处理器主循环。
//ae.c文件,事件处理器主循环,运行事件处理器,一直到服务器关闭为止
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 如果有需要在事件处理前执行的函数,那么运行它
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 开始处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
//ae.c文件,处理时间事件&文件时间
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
/* Nothing to do? return ASAP */
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0;
/* Note that we want call select() even if there are no
* file events to process as long as we want to process time
* events, in order to sleep until the next time event is ready
* to fire. */
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
// 获取最近的时间事件
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
// 如果时间事件存在的话
// 那么根据最近可执行时间事件和现在时间的时间差来决定文件事件的阻塞时间
long now_sec, now_ms;
/* Calculate the time missing for the nearest
* timer to fire. */
// 计算距今最近的时间事件还要多久才能达到
// 并将该时间距保存在 tv 结构中
aeGetTime(&now_sec, &now_ms);
tvp = &tv;
tvp->tv_sec = shortest->when_sec - now_sec;
if (shortest->when_ms < now_ms) {
tvp->tv_usec = ((shortest->when_ms+1000) - now_ms)*1000;
tvp->tv_sec --;
} else {
// 执行到这一步,说明没有时间事件
// 那么根据 AE_DONT_WAIT 是否设置来决定是否阻塞,以及阻塞的时间长度
/* If we have to check for events but need to return
* ASAP because of AE_DONT_WAIT we need to set the timeout
* to zero */
if (flags & AE_DONT_WAIT) {
// 设置文件事件不阻塞
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
/* Otherwise we can block */
// 文件事件可以阻塞直到有事件到达为止
tvp = NULL; /* wait forever */
}
}
// 处理文件事件,阻塞时间由 tvp 决定
numevents = aeApiPoll(eventLoop, tvp);//aeApiPoll获取已就绪事件by gs
for (j = 0; j < numevents; j++) {
// 从已就绪数组中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
/* note the fe->mask & mask & ... code: maybe an already processed
* event removed an element that fired and we still didn't
* processed, so we check if the event is still valid. */
// 读事件
if (fe->mask & mask & AE_READABLE) {
// rfired 确保读/写事件只能执行其中一个
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
processed++;
}
}
// 执行时间事件
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
//返回处理的时间事件+文件事件总数
return processed;
}
6. 事件触发
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
// 处理文件事件,阻塞时间由 tvp 决定
numevents = aeApiPoll(eventLoop, tvp);//aeApiPoll获取已就绪事件by gs
for (j = 0; j < numevents; j++) {
// 从已就绪数组中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
/* note the fe->mask & mask & ... code: maybe an already processed
* event removed an element that fired and we still didn't
* processed, so we check if the event is still valid. */
// 读事件
if (fe->mask & mask & AE_READABLE) {
// rfired 确保读/写事件只能执行其中一个
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
processed++;
}
...
}
其中,aeApiPoll用来收集就绪的文件时间,如果底层I/O多路复用机制采用epoll模式的话,对应ae_epoll.c文件。
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
// 等待时间
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
// 有至少一个事件就绪?
if (retval > 0) {
int j;
// 为已就绪事件设置相应的模式
// 并加入到 eventLoop 的 fired 数组中
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
// 返回已就绪事件个数
return numevents;
}