
最近查了一个线上页面503的问题,对nginx各种状态有了进一步的了解,简单的总结下。
由于现在的开发语言为python,所以拿nginx+uwsgi进行举例说明。
主要讲 504、502、499对应的场景
一个http请求处理流程
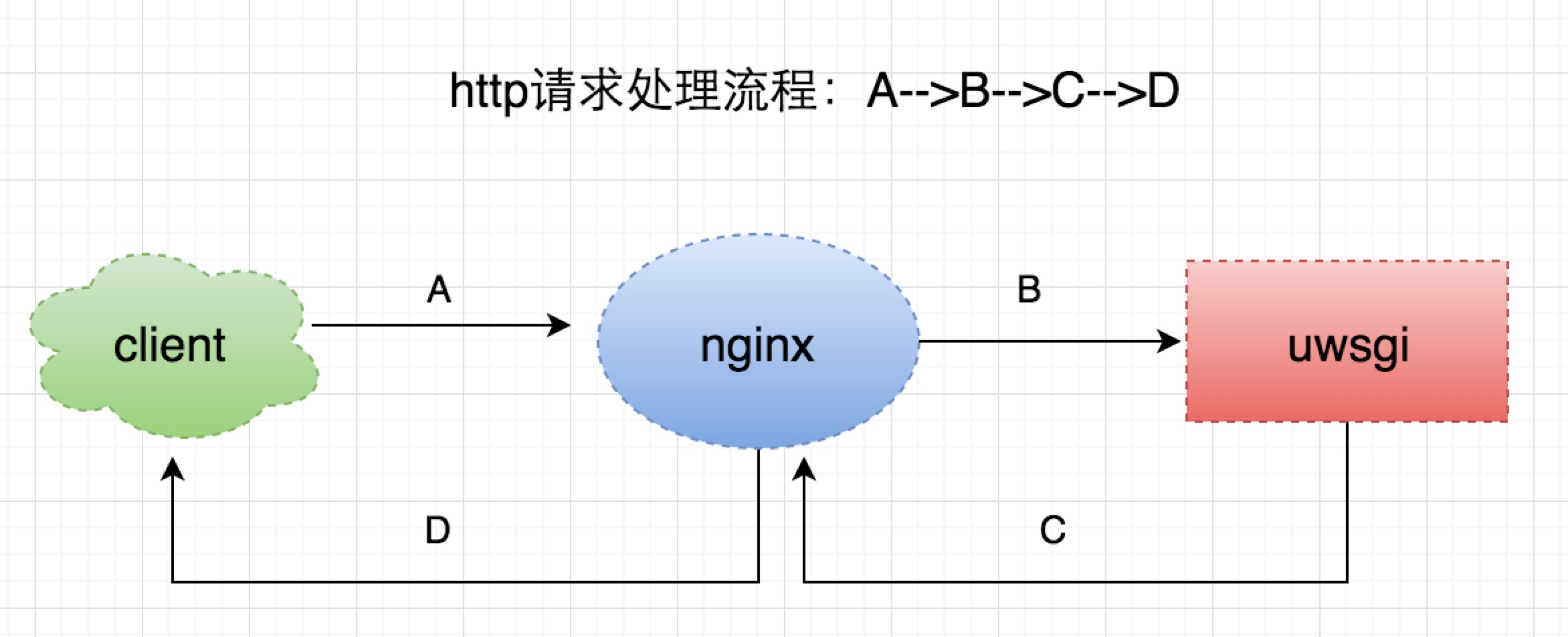
一个普通的http请求处理流程,如上图所示:
A client端发起请求给nginx
B nginx处理后,将请求转发到uwsgi,并等待结果
C uwsgi处理完请求后,返回数据给nginx
D nginx将处理结果返回给客户端
每个阶段都会有一个预设的超时时间,由于网络、机器负载、代码异常等等各种原因,如果某个阶段没有在预期的时间内正常返回,就会导致这次请求异常,进而产生不同的状态码。
504
504主要是针对B、C阶段
一般我们的nginx配置中会有
location / {
...
uwsgi_connect_timeout 6s;
uwsgi_send_timeout 6s;
uwsgi_read_timeout 10s;
uwsgi_buffering on;
uwsgi_buffers 80 16k;
...
}
这个代表nginx与上游服务器(uwsgi)通信的超时时间,也就是说,如果在这个时间内,uwsgi没有响应,则认为这次请求超时,返回504状态码。
具体的日志如下:
access_log
[16/May/2016:22:11:38 +0800] 10.4.31.56 201605162211280100040310561523 15231401463407888908 10.*.*.* 127.0.0.1:8500 "GET /api/media_article_list/?count=10&source_type=0&status=all&from_time=0&item_id=0&flag=2&_=1463407896337 HTTP/1.1" 504 **.***.com **.**.**.39, **.**.**.60 10.000 10.000 "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36" ...
error_log
2016/05/16 22:11:38 [error] 90674#0: *947302032 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.6.19.81, server: **.***.com, request: "GET /api/media_article_list/?count=10&source_type=0&status=all&from_time=0&item_id=0&flag=2&_=1463407896337 HTTP/1.1", upstream: "http://127.0.0.1:8500/**/**/api/media_article_list/?count=10&source_type=0&status=all&from_time=0&item_id=0&flag=2&_=1463407896337", host: "mp.toutiao.com", referrer: "https://**.***.com/articles/?source_type=0"
error_log中upstream timed out (110: Connection timed out) while reading response header from upstream,意思是说,在规定的时间内,没有从header中拿到数据,即uwsgi没有返回任何数据。
502
502主要针对B 、C阶段
产生502的时候,对应的error_log中的内容会有好几种,
access_log
[16/May/2016:16:39:49 +0800] 10.4.31.56 201605161639490100040310562612 2612221463387989972 10.6.19.81 127.0.0.1:88 "GET /articles/?source_type=0 HTTP/1.1" 503 **.***.com **.**.**.4, **.**.**.160 0.000 0.000 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "uuid=\x22w:546d345b86ca443eb44bd9bb1120e821\x22; tt_webid=15660522398; lasttag=news_culture; sessionid=f172028cc8310ba7f503adb5957eb3ea; sid_tt=f172028cc8310ba7f503adb5957eb3ea; _ga=GA1.2.354066248.1463056713; _gat=1"
error_log
2016/05/16 16:39:49 [error] 90693#0: *944980723 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 10.6.19.80, server: **.***.com, request: "GET /articles/ HTTP/1.1", upstream: "http://127.0.0.1:8500/**/**/articles/", host: "**.***.com", referrer: "http://**.***.com/new_article/"
列一下常见的几种502对应的 error_log:
recv() failed (104: Connection reset by peer) while reading response header from upstreamupstream prematurely closed connection while reading response header from upstreamconnect() failed (111: Connection refused) while connecting to upstream- …
这些都代表,在nginx设置的超时时间内,上游uwsgi没有给正确的响应(但是是有响应的,不然如果一直没响应,就会变成504超时了),因此nginx这边的状态码为502。
上面access_log中为啥是503呢?
这个是因为nginx upstream的容灾机制。 如果nginx有如下配置:
upstream app_backup {
server 127.0.0.1:8500 max_fails=3 fail_timeout=5s;
server 127.0.0.1:88 backup;
}
-
max_fails=3 说明尝试3次后,会认为“ server 127.0.0.1:8500” 失效,于是进入 “server 127.0.0.1:88 backup”,即访问本机的88端口;
-
nginx upstream的容灾机制,默认情况下,Nginx 默认判断失败节点状态以connect refuse和time out状态为准,不过我们的location里加了这个配置:
proxy_next_upstream error http_502;
proxy_connect_timeout 1s;
proxy_send_timeout 6s;
proxy_read_timeout 10s;
proxy_set_header Host $host;
- 这个配置是说,对于http状态是502的情况,也会走upstream的容灾机制;
概括一下就是,如果连续有3次(max_fails=3)状态为502的请求,则会任务这个后端server 127.0.0.1:8500 挂掉了,在接下来的5s(fail_timeout=5s)内,就会访问backup,即server 127.0.0.1:88 ,看下88端口对应的是什么:
server {
listen 88;
access_log /var/log/nginx/failover.log;
expires 1m;
error_page 500 502 503 504 /500.html;
location / {
return 503;
}
location = /500.html {
root /**/**/**/nginx/5xx/;
}
}
- 这个的意思就是,对于访问88端口的请求,nginx会返回503状态码,同时返回/opt/tiger/ss_conf/nginx/5xx/这个路径下的500.html文件。
- 因此,access_log中看到的是503
499
client发送请求后,如果在规定的时间内(假设超时时间为500ms)没有拿到nginx给的响应,则认为这次请求超时,会主动结束,这个时候nginx的access_log就会打印499状态码。
A+B+C+D > 500ms
其实这个时候,server端有可能还在处理请求,只不过client断掉了连接,因此处理结果也无法返回给客户端。
499如果比较多的话,可能会引起服务雪崩。 比如说,client一直在发起请求,客户端因为某些原因处理慢了,没有在规定时间内返回数据,client认为请求失败,中断这次请求,然后再重新发起请求。这样不断的重复,服务端的请求越来越多,机器负载变大,请求处理越来越慢,没有办法响应任何请求。。
499 这个待补充。。










